So I've been looking through the CG examples to get my head around some of it. The 2D stuff was fairly simple, just take in the vertices and does whatever, then outputs no problem. But then hit the 3D example program and was blasted in the face by more matrices than I knew what to do with.
So I consulted the bible of CG (Nvidia Tutorials) and went down the rabbit hole. Chapter 4 in the tutorial is where I needed to be. To reinforce what I've learned I'm going to attempt and explain what exactly the chapter talks about. It begins with some easy stuff about coordinate systems and the pipeline, then gets into the heart of the matter.
We begin at object/model space, which is the coordinate system for the object itself. Each vertex in the 3D object can (of course) be placed somewhere in the object space, with a vector to store all the translation/rotation info. Although not always shown, the w value is always there if you can't see it. It is more handy to use the 4-value vector because it makes all the 4x4 matrices much easier later (I'll get to it!)
Speaking of which, to get the object in world space you must combine all the rotations and translations into a homogeneous 4x4 matrix. Each object in the world have its own matrix to define where it is and its orientation etc. This way everything is relevant to the other objects in the world. These transformations can be concatenated to define the precise location of each object. Now with everything there, we need to look at it.
Eye space is the next stage, and it involves where we will be looking at the world from. In eye space, the camera or 'eye' will be at the origin and everything else will be relative to it in this coordinate system. To transform the world into eye space, the view transform must be done. This usually involves some sort of translation to offset all the other objects compared to the camera. Once you figure out where you want the camera, you multiply its homogenous 4x4 matrix by the model one to get the modelview matrix.
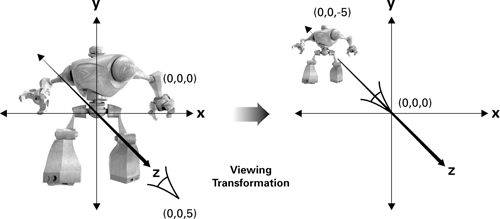 |
| Creating the modelview matrix. |
This results in the projmodelview matrix and is what makes up where the fragments are. In OpenGL the clip space will divide by the w to get each of x, y, z between -1 and 1. This means that the vectors are now normalized in the clip space. The final fragments are then sent through to be rasterized by the GPU, which then is displayed on the screen.
Hopefully I got this more or less. Now to do the hard part and actually figure how all this code works..


